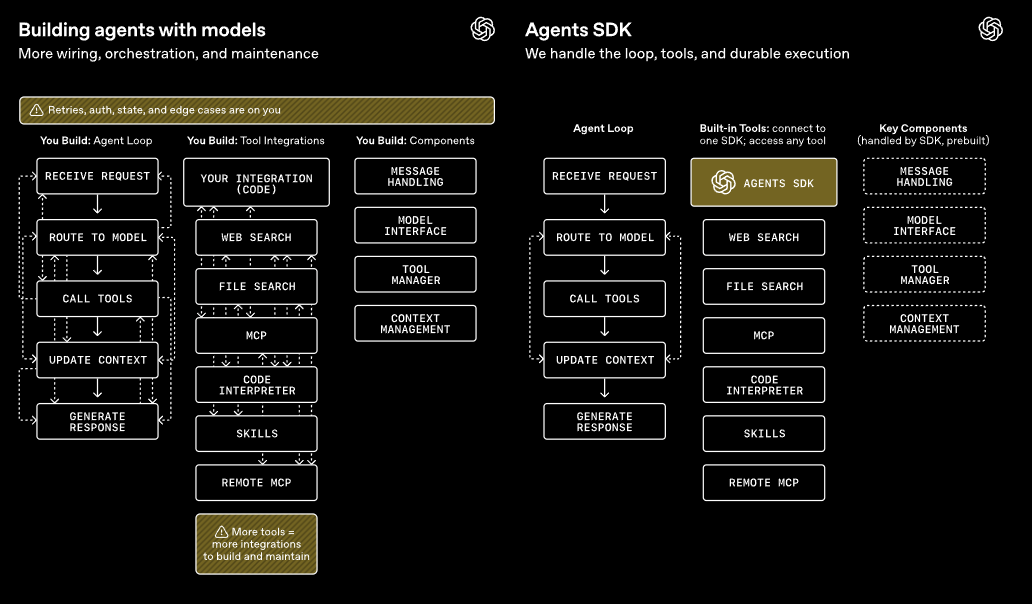
Adobe stellt den Firefly AI Assistant vor, einen neuen KI-Assistenten, der komplexe kreative Arbeitsabläufe über eine einzige Chat-Oberfläche steuert. Der Assistent verbindet Adobes Apps wie Photoshop, Illustrator, Premiere und Lightroom. Nutzer beschreiben in eigenen Worten, was sie erstellen wollen, und der Assistent führt die nötigen Schritte automatisch aus. Nutzer können jederzeit eingreifen.
Sogenannte "Creative Skills" ermöglichen es, mehrstufige Abläufe mit einem einzigen Befehl zu starten, etwa die Anpassung eines Bildes für verschiedene Social-Media-Plattformen. Adobe plant zudem die Anbindung an Chat-Plattformen wie Anthropics Claude.
Der Assistent basiert auf dem Vorprojekt "Project Moonlight", das auf der Adobe MAX vorgestellt wurde. Zusätzlich erweitert Adobe Firefly um KI-Video- und Bildbearbeitung mit Audio-Optimierung, erweiterten Farbkontrollen und Bildanpassungen. Die Zahl der verfügbaren KI-Modelle wächst auf mehr als 30, neu dabei ist Kling 3.0. Die öffentliche Beta des AI Assistant soll in den kommenden Wochen starten.